

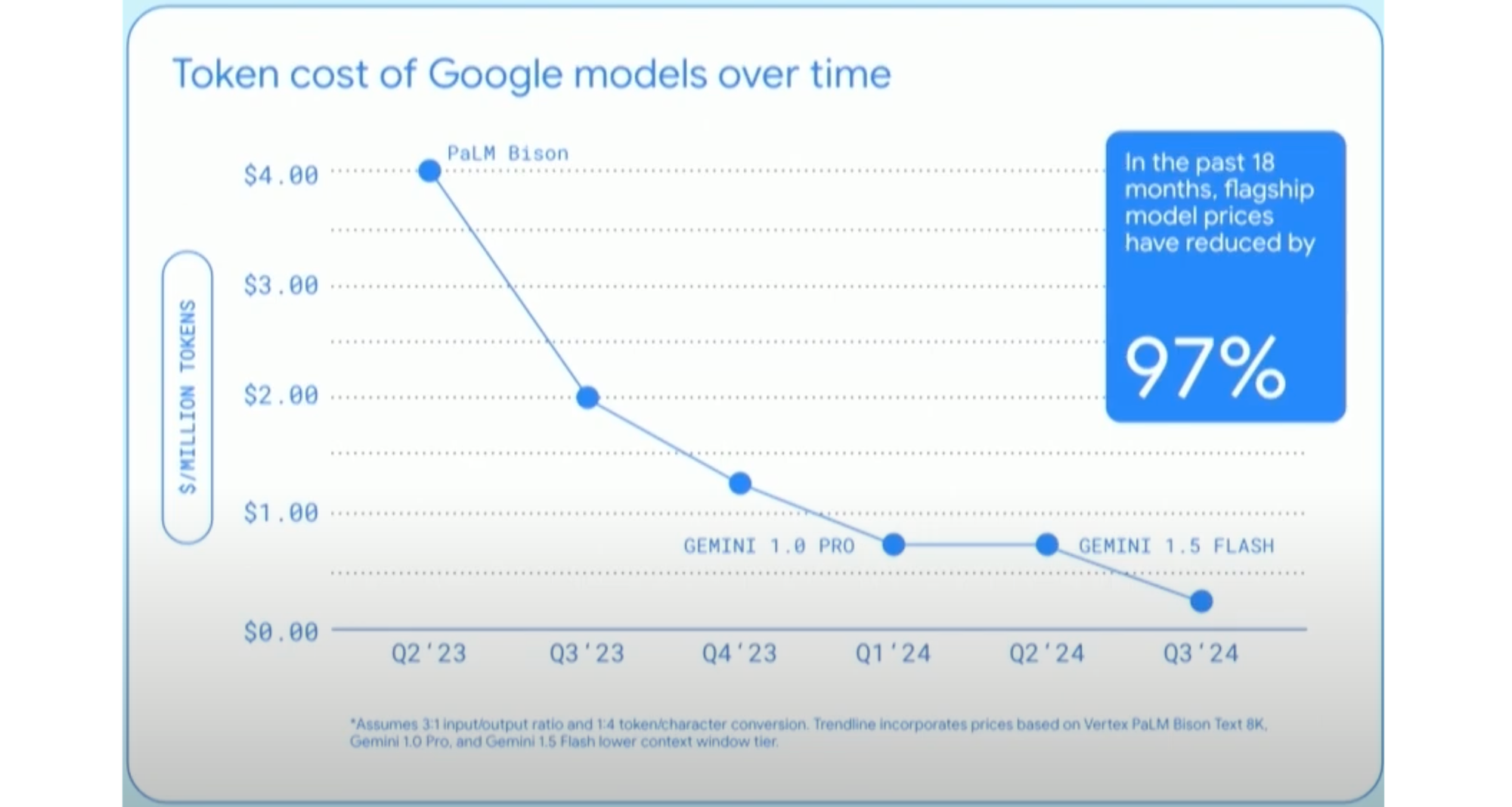
Token prices from large language models are in free fall, so let's talk about it. This graphic showing the collapse is from a presentation this week by Google's Sundar Pichai, and it is striking.
Background
First, however, a reminder what tokens are: Tokens are the smallest units of data that AI models are trained on. Their origins, are loosely, in natural language processing (NLP), where tokens generally referred to actual words. Tokens are now more closely associated with large language models (LLMs), where tokens are more variegated. They can be words, subwords, parts of words, and even punctuation. Tokens are the atomic units with which such models work.
Complicating things, tokens do not have to be text. They can be generated from images, video, time-series data, and even movement. But the key point remains: they are, in their context, the small unit with which models can usefully work.
How Models Use Tokens
Tokens are used in various ways, and that can confuse people. When you a train a model, it is tokenized data on which it is trained. Those tokens—in vectorized form—are what the model is working from, the elements from which it is generating the lattice of connections that we call learning.
This is a costly and time-consuming process, requiring massive amounts of data, huge numbers of processors, bandwidth, etc. While the costs of training are falling, they are not falling as the cost declines at the other end of the pipeline: inference, the process via which models produce responses to queries. That collapsing cost is what is shown in the above graph.
Why Token Costs Are Collapsing
As models grow larger and more efficient, the per-token cost of inference has dropped dramatically. It is worth understanding why. Here is a bulleted look at the main factors, as I see them:
- More Efficient Models:
- Optimized architectures: As LLMs evolve, models are being fine-tuned for inference efficiency, reducing the computational resources required for each query or response.
- Smarter tokenization: Modern models can reduce the number of tokens processed without sacrificing quality, driving down inference costs much faster than training costs, which involve much larger datasets and extended runtimes.
- Scaling Laws Favor Inference:
- Inference is simpler: Inference involves generating predictions based on a fixed, pre-trained model, while training requires updating the model's weights over millions or billions of iterations. This difference in complexity means that inference can benefit more from scaling hardware and algorithmic optimizations.
- Economies of scale: Once a model is trained, deploying it across a wide range of users for inference spreads the cost across many instances, leading to a faster decline in per-token inference costs.
- Specialized Hardware for Inference:
- Custom chips: Companies like Google and Nvidia have developed hardware (e.g., TPUs, GPUs) optimized for inference workloads, allowing inference to become cheaper and more efficient over time. These chips generally have higher throughput for inference tasks than for training tasks.
- Batch processing: Inference can be parallelized and batched more effectively. For instance, running multiple inference queries together on specialized hardware reduces overhead, leading to a quicker drop in cost compared to training, which requires more sequential processing.
- Less Data Required for Inference:
- Training is data-intensive: Training LLMs involves vast amounts of data, requiring longer computation times, more memory, and more power. In contrast, inference requires relatively small amounts of input data, making it easier to optimize and reduce costs.
- Static vs. dynamic costs: Training models involves dynamic and ongoing costs, whereas inference operates on a fixed model, meaning the cost-per-token during inference can fall dramatically once the model is trained and fine-tuned.
- Model Compression and Quantization:
- Smaller models for inference: Techniques like model pruning, quantization, and distillation allow companies to deploy smaller, faster versions of the same model for inference without major loss of performance. These compressed models are cheaper to run for inference.
- Inference Innovations Are a Focus:
- Industry focus on inference: Much of the recent innovation has focused on making inference cheaper, as it's the phase most visible to consumers. By contrast, training cost reductions are limited by the sheer computational demands of training large models, and training breakthroughs are less frequent.
What Collapsed Token Costs Mean For ... AI Companies
If you are an LLM company, and your business was to make bank from inference, you will need to rethink that. While at sufficient scale inference revenues will still be material, the pressure will not relent. Material charges for model responses cannot be the future, which will cause dramatic changes in how narrow AI vendors like OpenAI, Anthropic, and others who lack other business lines earn their keep. This favors Google, Microsoft, and Amazon as inference inevitably becomes more important.